
Immutability: The Dark Side
2016年06月05日 星期日, 发表于 深圳,中国
如果你对本文有任何的建议或者疑问, 可以在 这里提issues
FPer对OO批评最多的是:由于OO允许在运行时修改状态,从而无法做到引用透明(Referiential Transparency)。换句话说:对于同一个函数,使用相同的输入参数,每次调用返回的结果却不相同。比如:
struct Foo
{
int inc(int b)
{
a += b;
return a;
}
private:
int a = 1;
};
void f()
{
Foo foo;
std::cout << foo.inc(2) << std::endl; // 3
std::cout << foo.inc(2) << std::endl; // 5
}
但是,OO社区的人对此却并不买账。认为对象的状态虽然允许修改,但其实并没有改变引用透明性。因为函数Foo::inc事实上有一个隐藏参数this。站在这个角度,两次调用的输入参数其实并不相同。反过来,对于状态完全相同的两个对象,如果其它输入参数也相同,其输出也必然相同。Nothing Different!
但是,在多线程模式下,如果两个线程同时持有同一个可修改状态的对象,那么程序运行结果将会处于不确定状态。除非像FP那样,将对象修改为不可变的,每次计算都产生一个新的对象来作为输出。比如:
struct Foo
{
Foo(int a) : a(a) {}
Foo inc(int b) const
{
return a + b;
}
private:
int a = 1;
};
这就是多线程模式下的Shared Nothing策略。
另外,对于支持惰性求值(Lazy Evaluation)的语言,不可变性(Immutability)是必须被保证的。因为在非严格(non-strict)、惰性求值的语言里,表达式都是按需求值(call-by-need)的。换句话说,对于任意两个表达式,其估值顺序很可能是不确定的。这就意味着,如果两个表达式持有同一个可修改状态的对象,那么计算结果也会随着求值顺序的变化而变化。这也丧失了引用透明性。
当然,并不是所有的FP语言都支持惰性求值。而惰性求值本身也是个充满争议的选择。因而,对于严格求值的语言,不可变性的价值就仅限于并行计算。
因而,OO程序员的观点是:并行计算真正需要的是Shared Nothing。而Shared Nothing有更为廉价的手段来满足。而不是只有代价高昂的不可变性这一种选择。
比如,多线程间可以全部通过消息来通信,同样可以达到线程间Shared Nothing的目的。同时线程内部允许修改状态,又能够避免不必要的性能损失。两全其美!
而这正是多核时代绝大多数程序员的选择。这也是go-lang的并发策略:
Do not communicate by sharing memory; instead, share memory by communicating.
当然,FPer可以继续阐述不可变性的好处:由于其绝大部分代码天然就是Shared Nothing的,可以更容易的将任何一段代码投入并行运算。
这确实是一个无可比拟的优势。但在现实项目中,需要发挥这种优势的概率有多高,却是一个值得思考的问题。毕竟,不可变性不是免费的。在考虑它能发挥的价值的同时,也必须要为之付出的代价,把两个因素放到一起,结合项目的实际情况,做出务实的选择,才是一个合格的工程师应该具备的态度。
性能永远都是一个问题
很多FPer为了鼓吹FP在描述算法方面的优势时,总爱举这个例子:
quicksort [] = []
quicksort (p:xs) = (quicksort lesser) ++ [p] ++ (quicksort greater)
where
lesser = filter (< p) xs
greater = filter (>= p) xs
确实优雅的无与伦比。
对比之下,C语言版本的实现就就冗长的多:
void qsort(int a[], int lo, int hi)
{
int h, l, p, t;
if (lo < hi) {
l = lo;
h = hi;
p = a[hi];
do {
while ((l < h) && (a[l] <= p))
l = l+1;
while ((h > l) && (a[h] >= p))
h = h-1;
if (l < h) {
t = a[l];
a[l] = a[h];
a[h] = t;
}
} while (l < h);
a[hi] = a[l];
a[l] = p;
qsort( a, lo, l-1 );
qsort( a, l+1, hi );
}
}
不过那些FPer没有告诉你们故事的另一面:相对于C语言版本,那份看起来很优雅的Haskell实现,无论在时间效率还是空间效率方面,都糟糕的一塌糊涂。
Haskell是一门默认惰性求值的FP语言。从理论上,惰性求值可以可以让程序员可以站在更高抽象层面写程序,不用关心程序的执行顺序,语言的runtime会自动避免掉那些不必要的计算。
但惰性求值也不是免费的,对于暂时无需求值的表达式,需要以thunk的形式在内存中驻留,这就会导致不可控的空间占用。另外,由于需要不断的对是否已经求值进行判断,惰性求值也会付出一定的性能代价。
更为麻烦的是,作为一门惰性求值语言,正如我们之前所描述的,即便不考虑并行运算,只是因为其求值顺序的不确定,就会导致:即便在局部范围,每一个变量的不可变性也是必须的。
而这种不可变性对于性能的损耗,在很多“状态修改密集型”的算法面前,已经到了让人无法容忍的地步。
为了解决这类问题,不得不引入局部状态可修改的机制。其中之一,就是Monad.ST。
Monad.ST
Monad.ST的思想,就是引入引用的概念。也就是说,在一段计算中,不同的表达式,可以通过引用,指向同一个可修改的数据。不同表达式都可以根据需要对数据直接修改,而不是创建一份新数据的拷贝。
-- A MutVar# behaves like a single-element mutable array.
data MutVar# s a
-- Create MutVar# with specified initial value in specified state thread.
newMutVar# :: a -> State# s -> (# State# s, MutVar# s a #)
-- Read contents of MutVar#. Result is not yet evaluated.
readMutVar# :: MutVar# s a -> State# s -> (# State# s, a #)
-- Write contents of MutVar#.
writeMutVar# :: MutVar# s a -> a -> State# s -> State# s
这是个GHC编译器内部实现的MutVar#,从它的名字就可以看出,这是一个Mutable Variable。而其后缀符号#则说明,这是一个Unboxed Type。其三个主要函数用到了另外一个类型State#,也是一个GHC编译器内部实现的Unboxed Type。
data State# s
MutVar#是一个类型构造器,有两个参数:a是要存储的数据类型。而s则代表是状态。从逻辑上,MutVar#自身是一个引用,其引用的数据类型为a,而空间则从s所管理的存储上分配。如下图所示。
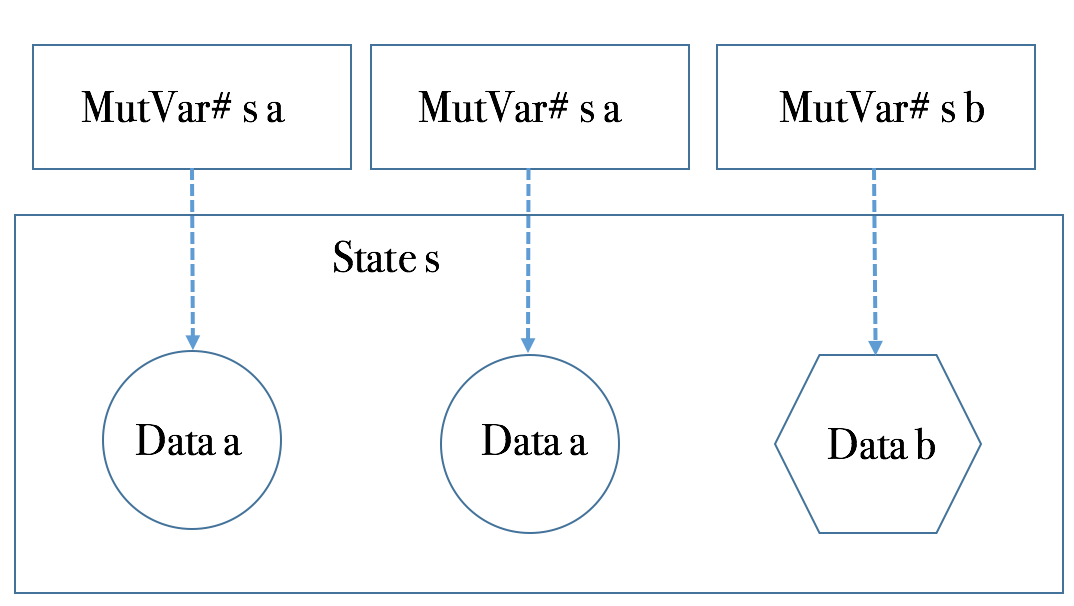
因而,我们可以写出下面的代码:
calc' :: (Num a) => State# s -> a -> a
calc' initS initV =
let (# s1, ref #) = newMutVar# initV initS
(# s2, v1 #) = readMutVar# ref s1
s3 = writeMutVar# ref (v1*10) s2
(# s4, v2 #) = readMutVar# ref s3
s5 = writeMutVar# ref (v2+20) s4
(# _finalS, finalV #) = readMutVar# ref s5
in finalV
从这段代码,可以清晰的看出一个三部曲操作模式:
- 在初始状态分配一个内容为初始值的数据,然后得到一个引用,以及被修改的状态;
- 不断通过引用,读写数据内容;注意,中间状态也在不断改变和传递;
- 最后,丢弃最终状态,从引用里读出数据返回。
在各个步骤间,变量的依赖,保证了即便在惰性求值下它们也会按照顺序处理。由于变化的是状态,状态依次在步骤间传递,这样的模式,是一种典型的State Monad。
newtype ST s a = ST (STRep s a)
type STRep s a = State# s -> (# State# s, a #)
instance Monad (ST s) where
return x = ST (\ s -> (# s, x #))
(ST m) >>= k
= ST $ \s ->
case (m s) of { (# new_s, r #) ->
case (k r) of { ST k2 -> (k2 new_s) }}
为了方便于Monad内部的代码编写,以及类型系统的约束,再提供如下辅助函数:
data STRef s a = STRef (MutVar# s a)
newSTRef :: a -> ST s (STRef s a)
newSTRef init = ST $ \s1# ->
case newMutVar# init s1# of { (# s2#, var# #) ->
(# s2#, STRef var# #) }
readSTRef :: STRef s a -> ST s a
readSTRef (STRef var#) = ST $ \s1# -> readMutVar# var# s1#
writeSTRef :: STRef s a -> a -> ST s ()
writeSTRef (STRef var#) val = ST $ \s1# ->
case writeMutVar# var# val s1# of { s2# ->
(# s2#, () #) }
modifySTRef :: STRef s a -> (a -> a) -> ST s ()
modifySTRef ref f = writeSTRef ref . f =<< readSTRef ref
然后就可以这样来写代码:
calc' :: Int -> ST s Int
calc' initV = do
ref <- newSTRef initV
v1 <- readSTRef ref
writeSTRef $ v1 * 10
v2 <- readSTRef ref
writeSTRef $ v2 + 20
readSTRef ref
需要特别指出的是,由于State和initV都是calc'函数的参数,因而calc'依然是个pure function,因而具备pure function的一切特质。比如引用透明。 其中每个步骤都是一个State Transformer,通过>>=,>>组合为一个更大的State Transformer,这也正是是ST名字的由来。
不过,calc'的结果依然还保存在ST Monad里。好在除了IO Monad之外,其它Monad的数据都可以从Monad里逃出。对于ST Monad,则是通过runST:
runST :: (forall s. ST s a) -> a
runST st = runSTRep (case st of { ST st_rep -> st_rep })
runSTRep :: (forall s. STRep s a) -> a
runSTRep st_rep = case st_rep realWorld# of
(# _, r #) -> r
在runST里,一个具体的状态实例作为参数传给了State Transformer。而这个实例,则是GHC编译器提供的readWorld#,其类型为GHC内置的ReadWorld#。
因而我们的例子可以写成:
calc :: Int -> Int
calc initValue = runST $ calc' initValue
对命令式的模仿
runST是一个重要的边界:它创建了一个初始状态,传递给State Transformer,然后得到一个最终状态,以及计算的结果。最后,抛弃掉最终状态,仅保留计算结果。
如果我们把这一系列的机制和命令式语言对应起来,可以看出,这完全是对命令式语言局部变量处理的模拟。
对于命令式语言,所有的局部变量都是在线程的栈上分配,从而修改了Stack的状态。随后所有的读写操作也都在栈上进行,不断修改Stack的状态。在一个函数处理结束后,在栈上分配的局部变量都会自动释放,关心的数据则当作函数的返回值返回。如下图所示。
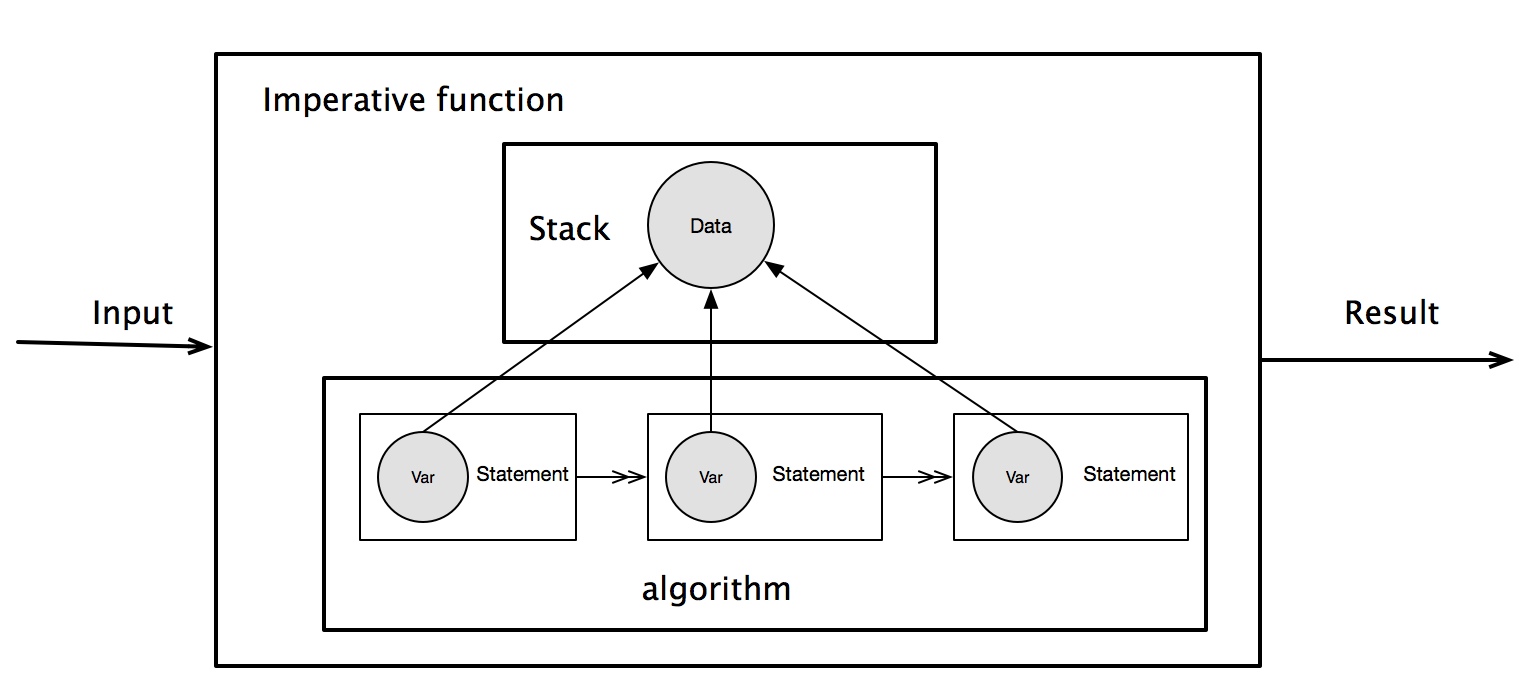
而在ST Monad里,runST对应的是命令式语言的函数,而Stack对应的则是State:在计算开始时,提供一个State,计算在State上分配数据,存取State的状态,等计算结束后,State的最终状态被抛弃,返回计算结果。如下图所示。
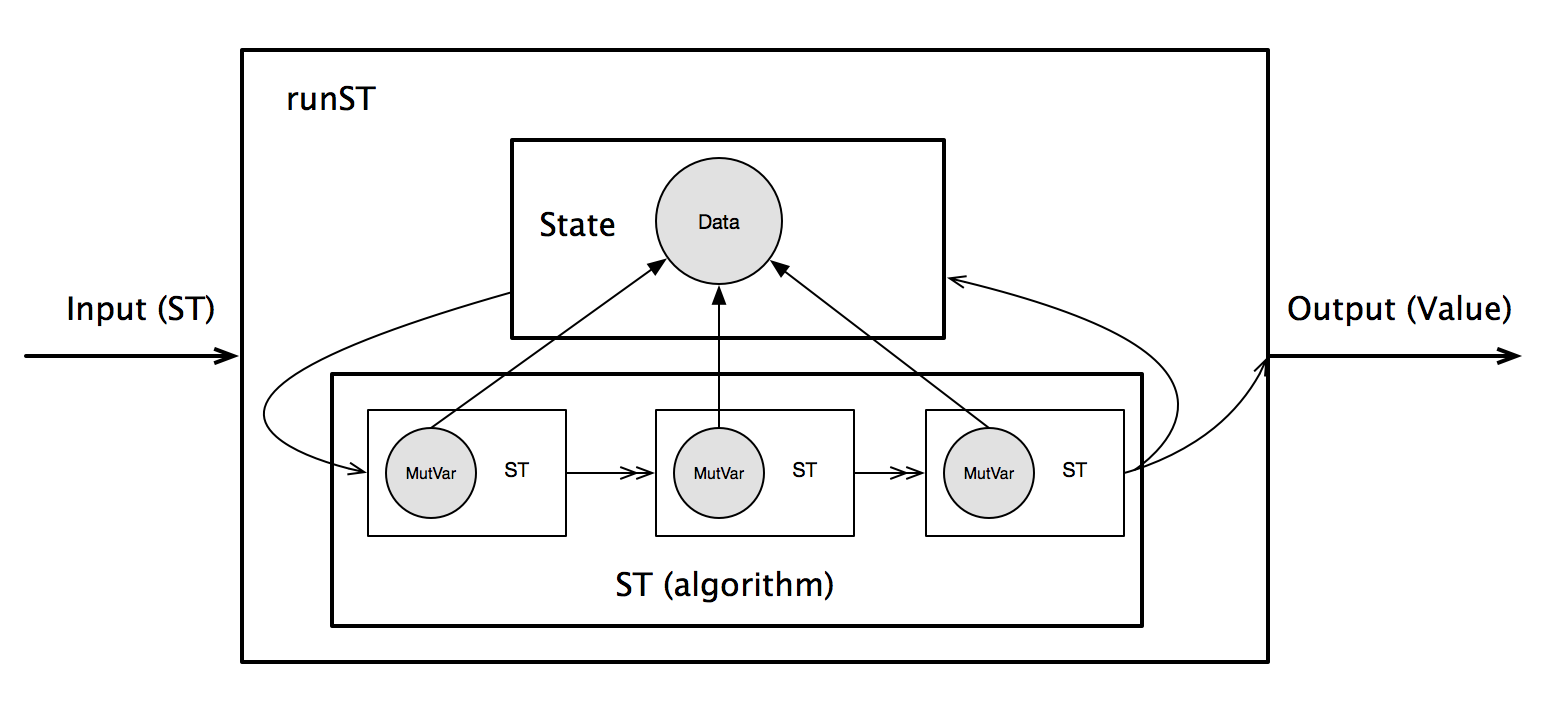
这样的模仿,相对于命令式语言的局部变量可变性,并未得到任何额外的好处。但很明显,命令式语言在这类问题上的处理要简洁的多。同时也说明了,允许局部变量的可修改性,对于引用透明和线程安全没有任何影响,只会带来简洁和性能。
Rank 2 Type
我们设想一下,在命令式语言里,在一个函数调用结束后,如果其在栈里的分配的数据不释放,可以被随后的函数访问,那么那些数据就与全局变量无异了。我们都知道,全局变量是违背Shared Nothing原则的。
通过上述对照,我们知道State是对Stack的模仿。在runST结束后,State也必须像Stack一样被释放,避免被其它计算继续使用,这才能保证线程安全。
可是,如果我们写下这样的代码:
f1 :: STRef s a -> ST s a
f1 ref = do
v <- readSTRef ref
writeSTRef $ v * 10
readSTRef ref
let ref = runST $ newSTRef 10
v1 = runST $ readSTRef ref
v2 = runST $ f1 ref
in ...
这就造成了ref在多个runST之间传递。对于惰性求值的语言而言,runST的求值顺序是不确定的,从而导致v1和v2计算结果的不确定。这就像多线程程序共享同一份数据,却没有任何措施来保证对共享数据访问的序列化一样,是一个严重的问题。
不过,ST设计者通过引入Rank 2 Types解决了这个问题。Rank 2 Types不属于Hindley-Milner类型系统的范畴。也不在haskell 98里。但这对于很多设计却又是比不可少的。
在Rank 1 Type的一个函数里,每个类型变量,只能被绑定为一个类型。这就导致了,如果一个高阶函数的某个参数是一个参数化多态(Parametric Polymorphism)函数,那么在这个高阶函数里,无论那个参数化多态函数被调用多少次,其类型变量所绑定的类型都必须是一致的。比如下面的代码就无法通过编译:
g :: (a -> a) -> (Bool, Char)
g f = (f True, f 'c')
因为,f在同一个函数g的上下文里,两次调用里,其类型变量a被绑定的类型是不同的:一个是Bool,一个是Char。
这明显是一个给程序员带来麻烦的问题。因而,GHC给出了一个扩展,叫Rank2Types。它允许程序员通过将上面例子中函数g的类型修改为:
g :: (forall a. a -> a) -> (Bool, Char)
某种程度上,你可以将Rank 2 Types理解为C++的Template Template Parameter技术,比如:
template <typename T, typename G,
template <typename E> class Container >
struct Foo
{
Container<T> tContainer;
Container<G> gContainer;
};
下面我们来看看为何Rank 2 Type可以解决runST状态泄漏的问题。我们先来推导一下表达式runST $ newSTRef 10的类型:
runST :: (forall s. ST s a) -> a
newSTRef 10 :: forall s. ST s (STRef s Int)
[STRef s Int ~ a]
因而,
runST $ newSTRef 10 :: (forall s. ST s (STRef s Int)) -> STRef s Int
其中,s已经出现在\(\forall s\)的限定范围之外,因而编译器将不会通过编译。
但是,如果runST的类型为forall s. ST s a -> a,上述类型则变为:
runST $ newSTRef 10 :: forall s. ST s (STRef s Int) -> STRef s Int
在这个类型里,两个s都在同一个限定符的作用范围内,因而它能够通过编译。
反过来,假设ref = runST $ newSTRef 10这样的代码通过了编译,它将被代入的表达式:runST $ readSTRef ref:
由此可见,s是环境中的自由变量,readVar ref的类型与runST所需的\(\forall s. ST\ \ s\ \ a\)类型不匹配,因而也无法通过编译。
因此,借助于Rank 2 Types的类型检查,程序员不可能写出能够让state从一个runST泄露的代码。从而保证了安全性。
模仿C语言算法
搞定了ST Monad之后,我们终于可以使用它所提供的机制来模仿C语言算法了:
import Control.Monad (when)
import Control.Monad.ST
import Data.Array.ST
import Data.Array.IArray
import Data.Array.MArray
qsort :: (IArray a e, Ix i, Enum i, Ord e) => a i e -> a i e
qsort arr = processArray quickSort arr
processArray :: (IArray a e, IArray b e, Ix i)
=> (forall s. (STArray s) i e -> ST s ()) -> a i e -> b i e
processArray f (arr :: a i e) = runST $ do
arr' <- thaw arr :: ST s (STArray s i e)
f arr'
unsafeFreeze arr'
quickSort :: (MArray a e m, Ix i, Enum i, Ord e) => a i e -> m ()
quickSort arr = qsort' =<< getBounds arr
where
qsort' (lo, hi) | lo >= hi = return ()
| otherwise = do
p <- readArray arr hi
l <- mainLoop p lo hi
swap l hi
qsort' (lo, pred l)
qsort' (succ l, hi)
mainLoop p l h | l >= h = return l
| otherwise = do
l' <- doTil (\l' b -> l' < h && b <= p) succ l
h' <- doTil (\h' b -> h' > l' && b >= p) pred h
when (l' < h') &\$& do
swap l' h'
mainLoop p l' h'
doTil p op ix = do
b <- readArray arr ix
if p ix b then doTil p op (op ix) else return ix
swap xi yi = do
x <- readArray arr xi
readArray arr yi >>= writeArray arr xi
writeArray arr yi x
这个版本,相对于C语言版本,已经比C的写法还要繁杂。但不幸的是,即便经过这样的努力,此版本的性能,虽然相对于之前那个简介而优雅的版本,得到了一定的提升,但其性能依然得到了这样的评价:
The program below is working very very slowly. It’s probably slowsort… :o)
终于,有高手看不过去了,干脆祭出unsafe大法:通过放弃编译器检查的安全性,来提高程序的性能,然后得到了这个版本:
import Data.Array.Base (unsafeRead, unsafeWrite)
import Data.Array.ST
import Control.Monad.ST
myqsort :: STUArray s Int Int -> Int -> Int -> ST s ()
myqsort a lo hi
| lo < hi = do
let lscan p h i
| i < h = do
v <- unsafeRead a i
if p < v then return i else lscan p h (i+1)
| otherwise = return i
rscan p l i
| l < i = do
v <- unsafeRead a i
if v < p then return i else rscan p l (i-1)
| otherwise = return i
swap i j = do
v <- unsafeRead a i
unsafeRead a j >>= unsafeWrite a i
unsafeWrite a j v
sloop p l h
| l < h = do
l1 <- lscan p h l
h1 <- rscan p l1 h
if (l1 < h1) then (swap l1 h1 >> sloop p l1 h1) else return l1
| otherwise = return l
piv <- unsafeRead a hi
i <- sloop piv lo hi
swap i hi
myqsort a lo (i-1)
myqsort a (i+1) hi
| otherwise = return ()
终于,得到了这样的评价:是C语言版本运行时间的2倍以内。
… reports that this version runs within 2x of the C version.
结论
对于命令式语言而言,对于一个函数内的局部变量的修改,并不会引入任何副作用,因为每个线程都有自己的栈,不同线程会从自己的栈上为局部变量分配空间。因而线程间也是100%的Shared Nothing。
但FP对于不可变性的坚持,让程序员在这类问题上也不得不付出不必要的代价。为了解决这类的问题,FP也不得不去模拟在命令式语言的行为。这这类的模拟行为必须有编译器的内建支持,否则,在Pure FP自身的语义下,是不可能存在reference to mutable variable这样的元素的。而这一切的努力,在命令式语言里,不过是再自然不过的内建支持。另外,即便付出这样的努力,由于FP自身的特点,其性能依然比C语言要慢的多。
由于变量的缺位,FP只能以递归的方式来处理循环问题。但一些FPer却把这种不得不为之的结果鼓吹为: 递归是描述问题最自然的方式。
但事实上,确实一些问题用递归描述起来更加自然,但同样也有一些问题,用迭代的方式描述起来更加自然。更不用说,在性能约束面前,很多无法自然描述为尾递归问题的算法,不得不修改为迭代算法,却又受语言能力所限,不得不用递归的语法表述迭代算法,让代码看起来更加晦涩。
而命令式语言,同时支持递归和迭代两种方式,其中一些(比如C++)也支持对于尾递归的优化。这就让程序员拥有了更加自由的选择。可以根据不同问题域做出最合理的决策。
因而,给出灵活度和自由度,让程序员自己根据需要做出决策,要比强制程序员——特别是真正的程序员——必须在所有情况下都必须遵守某种方式要更有价值。